A versatile system that optimizes and adapts data shuffling in distributed systems, simplifying complex operations and enhancing overall performance.
Problem:
Large-scale data analytics in modern data centers involve three main steps: workers process data independently (compute), preliminary results can be locally processed (combine), and data is reshaped for the next stage (shuffle). Poor planning in the shuffle phase can significantly impede system throughput and latency. This phase poses a primary bottleneck in data analytics on emerging cloud platforms, and optimizing it is challenging due to workload dependencies and evolving data center architectures, compounded by the growing complexity of big data systems using disaggregated storage and intricate network interactions.
Solution:
The inventors have proposed a templated shuffle (TeShu) layer that can adapt to application data and data center infrastructure, enabling it to serve as an extensible unified service layer common to all data analytics, on top of which existing and future systems can be built.
Technology:
TeShu is a technology that optimizes data shuffling in distributed systems for improved performance and adaptability. It offers customizable shuffle templates, simplifying adaptation across various upper-layer applications. TeShu's adaptive capabilities consider workload, combiner logic, shuffle patterns, and network topology, enhancing shuffle efficiency. It instantiates execution plans at runtime, directing the shuffle data for higher layers, and can be used as a service by various big data platforms. Moreover, its sampling-based approach dynamically adjusts to query workloads and network conditions, achieving accuracy with minimal data sampling.
Advantages:
- Reduces communication overhead by 66.8% to 89.8%, leading to more efficient utilization of network resources
- Simplifies the customization of shuffling processes, saving development time and effort
- Achieves high accuracy (above 90%) with minimal overhead, allowing for effective optimization without significant data sampling
- TeShu's adaptive features ensure that data shuffling adjusts to workload changes and network conditions, ensuring consistent performance
- Leads to a substantial increase in data processing speed, with execution time speedups ranging from 3.9x to 14.7x, depending on network conditions
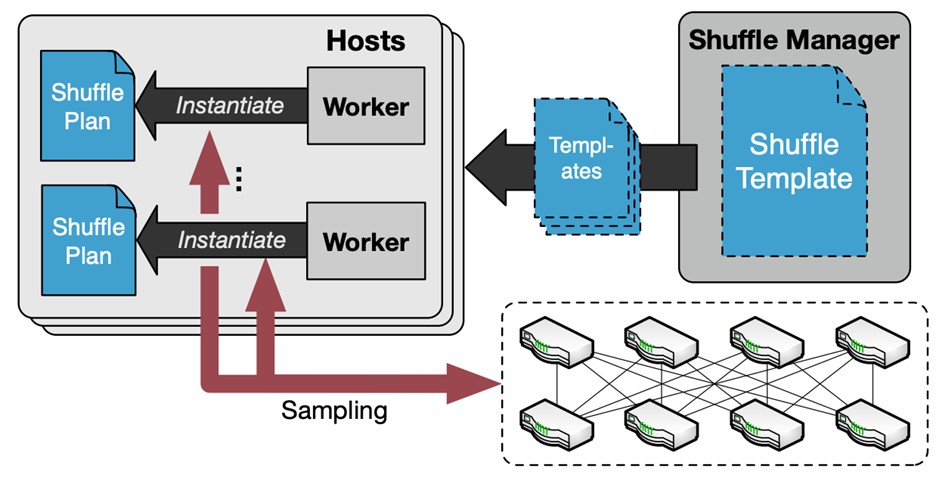
The architecture of TeShu. When shuffle is invoked, a shuffle manager ships shuffle templates to the application.
Intellectual Property:
- Provisional Application Filed
Case ID:
23-10483-tpNCS
Web Published:
2/1/2024
Patent Information:
| App Type |
Country |
Serial No. |
Patent No. |
File Date |
Issued Date |
Expire Date |